Cos’è RAID?
RAID (array ridondante di dischi indipendenti) è un modo per archiviare gli stessi dati in posizioni diverse su più dischi rigidi o unità a stato solido (SSD) per proteggere i dati in caso di guasto di un’unità. Tuttavia, esistono diversi livelli RAID e non tutti hanno l’obiettivo di fornire ridondanza.
Come funziona RAID
RAID funziona posizionando i dati su più dischi e consentendo alle operazioni di input/output (I/O) di sovrapporsi in modo bilanciato, migliorando le prestazioni. Poiché l’utilizzo di più dischi aumenta il tempo medio tra gli errori , l’archiviazione ridondante dei dati aumenta anche la tolleranza agli errori.
Gli array RAID appaiono al sistema operativo (SO) come una singola unità logica.
RAID impiega le tecniche di mirroring del disco o striping del disco. Il mirroring copierà i dati identici su più di un’unità. Le partizioni di striping aiutano a diffondere i dati su più unità disco. Lo spazio di archiviazione di ciascuna unità è suddiviso in unità che vanno da un settore di 512 byte fino a diversi megabyte. Le strisce di tutti i dischi sono interfogliate e indirizzate in ordine. Il mirroring del disco e lo striping del disco possono anche essere combinati in un array RAID.

In un sistema a utente singolo in cui sono archiviati record di grandi dimensioni, le strisce sono generalmente impostate per essere piccole (512 byte, ad esempio) in modo che un singolo record si estenda su tutti i dischi e sia possibile accedervi rapidamente leggendo tutti i dischi contemporaneamente tempo.
In un sistema multiutente, prestazioni migliori richiedono uno stripe sufficientemente ampio da contenere il record di dimensioni tipiche o massime, consentendo l’I/O su disco sovrapposto tra le unità.
Controller RAID
Un controller RAID è un dispositivo utilizzato per gestire le unità disco rigido in un array di archiviazione. Può essere utilizzato come livello di astrazione tra il sistema operativo ei dischi fisici, presentando gruppi di dischi come unità logiche. L’utilizzo di un controller RAID può migliorare le prestazioni e aiutare a proteggere i dati in caso di crash.
Un controller RAID può essere basato su hardware o software. In un prodotto RAID basato su hardware , un controller fisico gestisce l’intero array. Il controller può anche essere progettato per supportare formati di unità come Serial Advanced Technology Attachment e Small Computer System Interface. Un controller RAID fisico può anche essere integrato nella scheda madre di un server.
Con RAID basato su software , il controller utilizza le risorse del sistema hardware, come il processore centrale e la memoria. Sebbene svolga le stesse funzioni di un controller RAID basato su hardware, i controller RAID basati su software potrebbero non consentire un aumento delle prestazioni altrettanto elevato e possono influire sulle prestazioni di altre applicazioni sul server.
Se un’implementazione RAID basata su software non è compatibile con il processo di avvio di un sistema ei controller RAID basati su hardware sono troppo costosi, il firmware o RAID basato su driver è un’opzione potenziale.
I chip del controller RAID basati su firmware si trovano sulla scheda madre e tutte le operazioni vengono eseguite dall’unità di elaborazione centrale (CPU), simile al RAID basato su software. Tuttavia, con il firmware, il sistema RAID viene implementato solo all’inizio del processo di avvio. Una volta caricato il sistema operativo, il driver del controller assume la funzionalità RAID. Un controller RAID firmware non è costoso come un’opzione hardware, ma mette a dura prova la CPU del computer. Il RAID basato su firmware è anche chiamato RAID software assistito da hardware, RAID modello ibrido e RAID falso.
Livelli RAID
I dispositivi RAID utilizzano versioni diverse, chiamate livelli. Il documento originale che ha coniato il termine e sviluppato il concetto di configurazione RAID ha definito sei livelli di RAID, da 0 a 5. Questo sistema numerato ha consentito agli addetti IT di differenziare le versioni RAID. Da allora il numero di livelli è stato ampliato ed è stato suddiviso in tre categorie: livelli RAID standard, nidificati e non standard.
Livelli RAID standard
Questa configurazione ha lo striping ma non la ridondanza dei dati. Offre le migliori prestazioni, ma non fornisce tolleranza ai guasti.
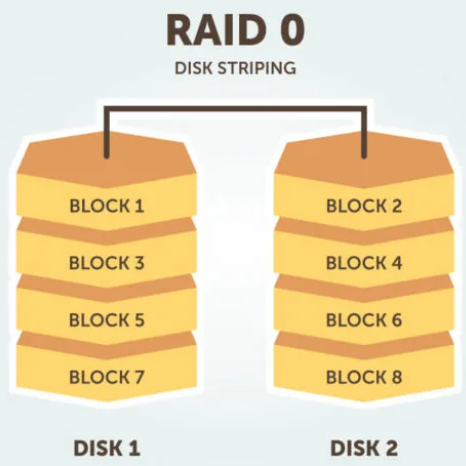
RAID 1.
Conosciuta anche come mirroring del disco , questa configurazione è composta da almeno due unità che duplicano l’archiviazione dei dati. Non ci sono strisce. Le prestazioni di lettura sono migliorate, poiché entrambi i dischi possono essere letti contemporaneamente. Le prestazioni di scrittura sono le stesse dell’archiviazione su disco singolo.
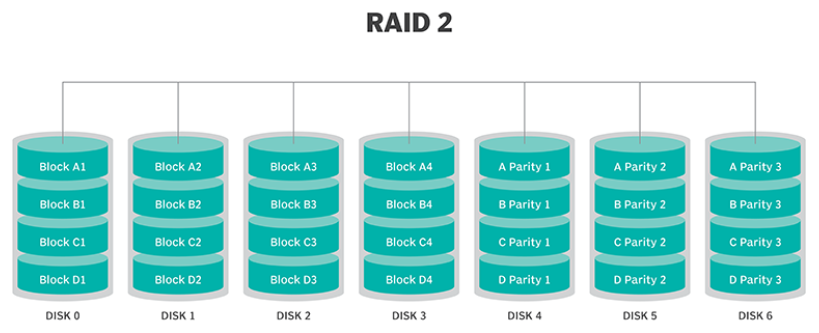
RAID 2.
Questa configurazione utilizza lo striping su più dischi, con alcuni dischi che memorizzano le informazioni di controllo e correzione degli errori (ECC). RAID 2 utilizza anche una parità di codice Hamming dedicata , una forma lineare di ECC. e non ha alcun vantaggio rispetto a RAID 3 e non viene più utilizzato.
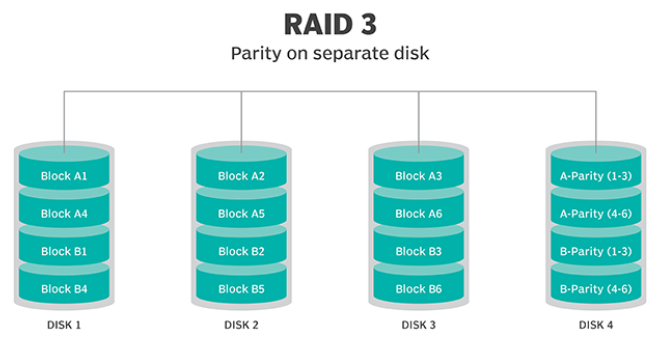
RAID 3.
Questa tecnica utilizza lo striping e dedica un’unità alla memorizzazione delle informazioni di parità . Le informazioni ECC incorporate vengono utilizzate per rilevare gli errori. Il recupero dei dati si ottiene calcolando le informazioni esclusive registrate sulle altre unità. Poiché un’operazione di I/O indirizza tutte le unità contemporaneamente, RAID 3 non può sovrapporre l’I/O. Per questo motivo, RAID 3 è la soluzione migliore per i sistemi a utente singolo con applicazioni di registrazione lunghe.
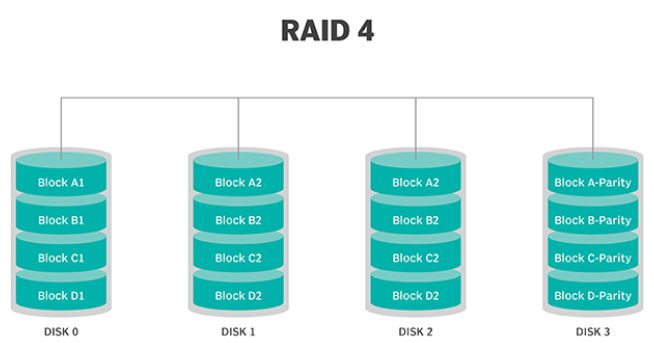
Raid 4.
Questo livello utilizza strisce grandi, il che significa che un utente può leggere i record da qualsiasi singola unità. Gli I/O sovrapposti possono quindi essere utilizzati per le operazioni di lettura. Poiché tutte le operazioni di scrittura sono necessarie per aggiornare l’unità di parità, non è possibile alcuna sovrapposizione di I/O.
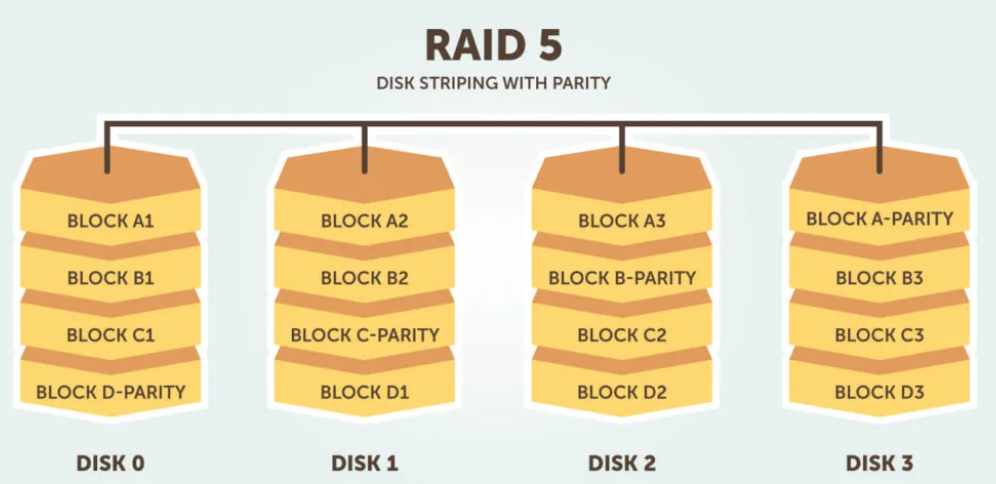
Raid 5.
Questo livello si basa sullo striping a livello di blocco di parità. Le informazioni sulla parità vengono distribuite su ciascuna unità, consentendo all’array di funzionare anche in caso di guasto di un’unità. L’architettura dell’array consente operazioni di lettura e scrittura su più unità. Ciò si traduce in prestazioni migliori di quelle di una singola unità, ma non così elevate come un array RAID 0. RAID 5 richiede almeno tre dischi, ma spesso si consiglia di utilizzare almeno cinque dischi per motivi di prestazioni.
Gli array RAID 5 sono generalmente considerati una scelta sbagliata per l’uso su sistemi ad alta intensità di scrittura a causa dell’impatto sulle prestazioni associato alla scrittura di dati di parità. Quando un disco si guasta, la ricostruzione di un array RAID 5 può richiedere molto tempo.
Raid 6.
Questa tecnica è simile a RAID 5, ma include un secondo schema di parità distribuito tra le unità dell’array. L’utilizzo di una parità aggiuntiva consente all’array di continuare a funzionare anche se due dischi si guastano contemporaneamente. Tuttavia, questa protezione aggiuntiva ha un costo. Gli array RAID 6 hanno spesso prestazioni di scrittura più lente rispetto agli array RAID 5.
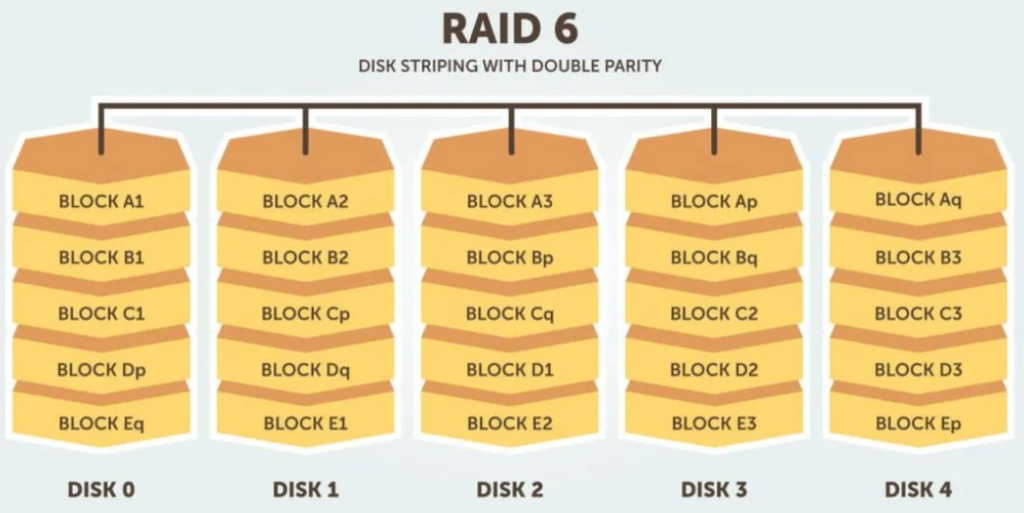
Livelli RAID nidificati
Alcuni livelli RAID basati su una combinazione di livelli RAID vengono definiti RAID annidati. Ecco alcuni esempi di livelli RAID nidificati.
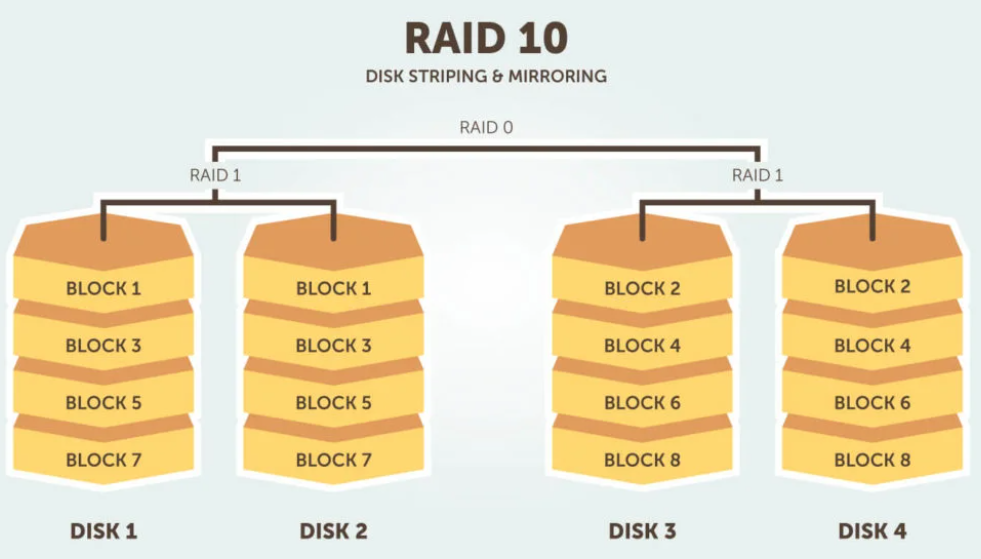
RAID 10 (RAID 1+0). Combinando RAID 1 e RAID 0 , questo livello è spesso indicato come RAID 10, che offre prestazioni più elevate rispetto a RAID 1, ma a un costo molto più elevato. In RAID 1+0, i dati vengono sottoposti a mirroring e i mirror vengono sottoposti a striping.
RAID 01 (RAID 0+1).
RAID 0+1 è simile a RAID 1+0, tranne per il fatto che il metodo di organizzazione dei dati è leggermente diverso. Anziché creare un mirror e quindi eseguirne lo striping, RAID 0+1 crea uno stripe set e quindi esegue il mirroring dello stripe set.
RAID 03 (RAID 0+3, noto anche come RAID 53 o RAID 5+3). Questo livello utilizza lo striping in stile RAID 0 per i blocchi del disco virtuale di RAID 3. Questo offre prestazioni più elevate rispetto a RAID 3, ma a un costo maggiore.
RAID 50 (RAID 5+0). Questa configurazione combina la parità distribuita RAID 5 con lo striping RAID 0 per migliorare le prestazioni RAID 5 senza ridurre la protezione dei dati.
Livelli RAID non standard
I livelli RAID non standard variano dai livelli RAID standard e sono generalmente sviluppati da aziende o organizzazioni per uso principalmente proprietario. Ecco alcuni esempi.
Raid 7.
Un livello RAID non standard basato su RAID 3 e RAID 4 che aggiunge la memorizzazione nella cache. Include un sistema operativo integrato in tempo reale come controller, memorizzazione nella cache tramite un bus ad alta velocità e altre caratteristiche di un computer autonomo.
RAID adattivo. Questo livello consente al controller RAID di decidere come memorizzare la parità sui dischi. Sceglierà tra RAID 3 e RAID 5. La scelta dipende da quale tipo di set RAID funzionerà meglio con il tipo di dati scritti sui dischi.
Linux MD RAID 10. Questo livello, fornito dal kernel Linux , supporta la creazione di array RAID nidificati e non standard. Il software RAID Linux può anche supportare la creazione di configurazioni RAID 0, RAID 1, RAID 4, RAID 5 e RAID 6 standard.
RAID hardware e RAID software
Come con i controller RAID, il RAID viene implementato tramite hardware o software. Il RAID basato su hardware supporta diverse configurazioni RAID ed è particolarmente adatto per RAID 5 e 6. La configurazione per RAID 1 hardware è utile per supportare il processo di avvio e unità dell’applicazione, mentre RAID 5 hardware è appropriato per array di archiviazione di grandi dimensioni. Sia l’hardware RAID 5 che 6 sono adatti per le prestazioni.
Il RAID basato su hardware richiede l’installazione di un controller dedicato nel server. I controller RAID nell’hardware sono configurati tramite il sistema I/O di base della scheda o Option ROM (memoria di sola lettura) prima o dopo l’avvio del sistema operativo. I produttori di controller RAID in genere forniscono anche strumenti software proprietari per i loro sistemi operativi supportati.
Il RAID basato su software è fornito da diversi sistemi operativi moderni. È implementato in diversi modi, tra cui:
Componente del file system;
come uno strato che astrae i dispositivi come un singolo dispositivo virtuale; E
come un livello che si trova sopra qualsiasi file system.
Questo metodo di RAID utilizza parte della potenza di calcolo del sistema per gestire una configurazione RAID basata su software. Ad esempio, Windows supporta il software RAID 0, 1 e 5, mentre MacOS di Apple supporta RAID 0, 1 e 1+0.
Vantaggi del RAID
I vantaggi del RAID includono quanto segue:
Migliore efficacia in termini di costi perché i dischi a basso prezzo vengono utilizzati in grandi quantità.
L’utilizzo di più dischi rigidi consente a RAID di migliorare le prestazioni di un singolo disco rigido.
Aumento della velocità e dell’affidabilità del computer dopo un arresto anomalo, a seconda della configurazione.
Le letture e le scritture possono essere eseguite più velocemente rispetto a una singola unità con RAID 0. Questo perché un file system viene suddiviso e distribuito su unità che lavorano insieme sullo stesso file.
C’è una maggiore disponibilità e resilienza con RAID 5. Con il mirroring, due unità possono contenere gli stessi dati, assicurando che una continui a funzionare se l’altra si guasta.
Svantaggi dell’uso del RAID
RAID ha i suoi limiti, tuttavia. Alcuni di questi includono:
I livelli RAID nidificati sono più costosi da implementare rispetto ai livelli RAID tradizionali, perché richiedono più dischi.
Il costo per gigabyte per i dispositivi di archiviazione è più elevato per il RAID nidificato perché molte delle unità vengono utilizzate per la ridondanza.
Quando un’unità si guasta, aumenta la probabilità che presto si guasti anche un’altra unità dell’array, il che probabilmente comporterebbe una perdita di dati. Questo perché tutte le unità in un array RAID sono installate contemporaneamente, quindi tutte le unità sono soggette alla stessa quantità di usura.
Alcuni livelli RAID, come RAID 1 e 5, possono sostenere solo un guasto di una singola unità.
Gli array RAID e i dati in essi contenuti sono vulnerabili finché un’unità guasta non viene sostituita e il nuovo disco non viene popolato di dati.
Poiché ora le unità hanno una capacità molto maggiore rispetto a quando il RAID è stato implementato per la prima volta, la ricostruzione delle unità guaste richiede molto più tempo.
Se si verifica un errore del disco, è possibile che i dischi rimanenti contengano settori danneggiati o dati illeggibili, il che potrebbe rendere impossibile la ricostruzione completa dell’array.
Tuttavia, i livelli RAID nidificati risolvono questi problemi fornendo un maggior grado di ridondanza, riducendo significativamente le possibilità di un errore a livello di array dovuto a guasti simultanei del disco.
Quando dovresti usare il RAID?
I casi in cui è utile disporre di una configurazione RAID includono:
- Quando è necessario ripristinare una grande quantità di dati. Se un’unità si guasta e i dati vengono persi, tali dati possono essere ripristinati rapidamente, poiché questi dati vengono archiviati anche in altre unità.
- Quando il tempo di attività e la disponibilità sono fattori aziendali importanti. Se è necessario ripristinare i dati, è possibile farlo rapidamente senza tempi di inattività.
- Quando si lavora con file di grandi dimensioni. RAID fornisce velocità e affidabilità quando si lavora con file di grandi dimensioni.
- Quando un’organizzazione deve ridurre il carico sull’hardware fisico e aumentare le prestazioni complessive. Ad esempio, una scheda RAID hardware può includere memoria aggiuntiva da utilizzare come cache.
- In caso di problemi con il disco I/O. RAID fornirà un throughput aggiuntivo leggendo e scrivendo dati da più unità, invece di dover attendere che un’unità esegua le attività.
- Quando il costo è un fattore. Il costo di un array RAID è inferiore rispetto al passato e i dischi a basso prezzo vengono utilizzati in gran numero, rendendolo più economico.
Storia del raid
Il termine RAID è stato coniato nel 1987 da David Patterson, Randy Katz e Garth A. Gibson. Nel loro rapporto tecnico del 1988, “A Case for Redundant Arrays of Inexpensive Disks (RAID)”, i tre sostenevano che un array di unità economiche poteva battere le prestazioni delle unità disco più costose dell’epoca. Utilizzando la ridondanza, un array RAID potrebbe essere più affidabile di qualsiasi unità disco.
Sebbene questo rapporto sia stato il primo a dare un nome al concetto, l’uso di dischi ridondanti era già stato discusso da altri. Gus German e Ted Grunau di Geac Computer Corp. si riferirono per primi a questa idea chiamandola MF-100. Norman Ken Ouchi di IBM ha depositato un brevetto nel 1977 per la tecnologia, che in seguito è stata denominata RAID 4. Nel 1983, Digital Equipment Corp. ha spedito le unità che sarebbero diventate RAID 1 e nel 1986 è stato depositato un altro brevetto IBM per quello che sarebbe diventato RAID 5. Patterson, Katz e Gibson hanno anche esaminato ciò che veniva fatto da aziende come Tandem Computers, Thinking Machines e Maxstor per definire le loro tassonomie RAID .
Sebbene i livelli di RAID elencati nel rapporto del 1988 dessero essenzialmente nomi a tecnologie già in uso, la creazione di una terminologia comune per il concetto ha contribuito a stimolare il mercato dell’archiviazione dei dati a sviluppare più prodotti di array RAID.
Secondo Katz, il termine economico nell’acronimo è stato presto sostituito con indipendente dai fornitori del settore a causa delle implicazioni dei bassi costi.
Il futuro del RAID
RAID non è del tutto morto, ma molti analisti affermano che la tecnologia è diventata obsoleta negli ultimi anni. Alternative come la codifica di cancellazione offrono una migliore protezione dei dati, anche se a un prezzo più elevato, e sono state sviluppate con l’intenzione di affrontare i punti deboli del RAID. Con l’aumentare della capacità dell’unità, aumenta anche la possibilità di errore con un array RAID e le capacità aumentano costantemente.
Si ritiene inoltre che l’aumento degli SSD allevi la necessità di RAID. Gli SSD non hanno parti mobili e non si guastano tanto spesso quanto i dischi rigidi. Gli array SSD utilizzano spesso tecniche come il livellamento dell’usura invece di fare affidamento su RAID per la protezione dei dati. Gli SSD moderni sono abbastanza veloci che i server moderni potrebbero non aver bisogno del leggero aumento delle prestazioni offerto da RAID. Tuttavia, possono ancora essere attualmente utilizzati per prevenire la perdita di dati.
L’hyperscale computing elimina anche la necessità di RAID utilizzando server ridondanti invece di unità ridondanti.
Tuttavia, il RAID rimane una parte radicata dell’archiviazione dei dati ei principali fornitori di tecnologia continuano a rilasciare prodotti RAID. Per esempio:
IBM offre IBM Distributed RAID, o DRAID, con il suo Spectrum Virtualize V8.3, che promette di aumentare le prestazioni RAID.
L’ultima versione della tecnologia Intel Rapid Storage supporta RAID 0, RAID 1, RAID 5 e RAID 10.
Il software di gestione NetApp OnTap utilizza RAID-DP, o doppia parità, o RAID 4 per proteggere da un massimo di tre guasti simultanei delle unità.
La piattaforma Dell EMC Unity supporta RAID 5, 6 e 10.